스펙터와 멜트다운 공격 2: 스펙터
스펙터 멜트다운 공격 원리 이해를 위한 컴퓨터 구조 바로가기
본 포스트에서는 스펙터 공격의 핵심원리를 설명한다.
Spectre
스펙터 공격의 핵심 코드는 다음과 같다.

악명높은 스펙터 공격의 핵심 코드는 매우 단순하다. 각 요소의 설명은 다음과 같다.

위 코드를 포함한 전체 스펙터 공격이 어떻게 동작하는지 요약하자면 다음과 같다.
A. 워밍업: if문 안의 조건이 참이 되도록 x를 세팅한다. 코드를 여러번 반복시켜 CPU가 조건문이 참이 될 것이라 예상하도록 만든다.
B. 공격시작: if문 안의 조건문이 거짓이 되면서 array1[x]가 타겟 프로그램의 메모리 영역을 향하도록 x값을 설정한다.
C. 프로그램의 논리대로라면, if문 안의 조건이 거짓이기 때문에 CPU가 두번째 줄 명령어를 실행하지 않아야 한다.
D. 그러나 여기서 CPU는 내부적으로는 두번째 줄 명령어를 미리 실행한다 (Branch Prediction 기법 때문에). 다만 조건문이 거짓이므로 결과를 실제로 y에 저장하지는 않는다.
E. D에서의 명령어 실행이 array1[x] 값을 읽어왔기 때문에 array1[x]의 값이 캐쉬 메모리에 올라가게 된다 (후에 다시 설명). 이 때문에 Flush+Reload 기법을 사용하면 해당 값을 알 수 있게 된다.
아래의 글에서는 스펙터 공격을 가능케 하는 Branch prediction과 Flush+Reload 기법에 대해 설명한다.
Branch Prediction
스펙터 공격은 Branch Prediction의 허점을 이용한다. 해당 기법은 현대 CPU에서는 성능향상을 위해 대부분의 CPU에서 사용하는 기법이다.
배경을 잠시 설명하자면, 1900년대 후반에 CPU성능이 발전함에 따라 CPU들은 한 사이클 (CPU 시간의 단위) 에 여러개의 명령어를 처리할 수 있게 되었다. 그런데 한 가지 문제점이 발생했다.
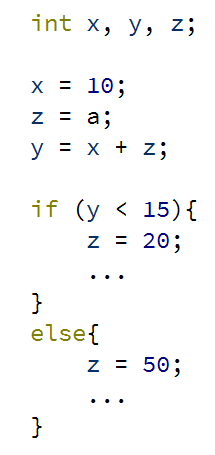
위 코드에서 if 문 안의 조건은 참 혹은 거짓이 될 수 있는데, 문제는 CPU가 더 많은 명령어들을 처리할 수 있음에도 if 문 조건이 참인지 거짓인지 밝혀질때까지는 다음 명령어가 무엇이 될지 알 수 없다는 것이다.
예를들면, 위 프로그램에서는 y가 15보다 작으면 z에 20을 넣고, 아니면 50을 넣는다. y와 z의 값은 실행을 해봐야지만 알 수 있다.
이를 극복하기 위해 엔지니어들은 Branch prediction (분기예측) 기법을 도입했다. 조건문이 참일지 거짓일지는 모르지만 미리 하나를 찍어서정하고 다음 명령어들을 미리 실행해 놓는 것이었다. 만약 맞춘다면 미리 명령어들을 실행해 놓을 수 있으므로 성능이 향상된다. 최근의 Branch prediction은 평균 약 95% 이상의 정확도를 보여준다고 보고되며, 본 기법을 통해 현대 CPU의 성능은 크게 향상되었다.
CPU는 조건문이 나오면 결과를 예측해서 미리 다음 명령어들을 실행한다.
만약 Branch prediction 예측이 틀리면, CPU는 미리 실행해 두었던 명령어들을 취소한다. 때문에 예측되어 실행된 명령어들의 실행은 취소된다.
그러나, 실행취소된 명령어에서 읽은 데이터가 캐쉬 메모리에 올라간다는 사실이 밝혀졌다. 그리고 이 때문에 Flush+Reload 기법을 사용하면 데이터를 읽어올 수 있다.
Flush+Reload
Flush+Reload는 캐쉬 메모리 (Cache Memory) 를 이용해 메모리 데이터를 간접적으로 읽어오는 부채널 공격의 일종이다. 여기서 잠시 캐쉬 메모리에 대해 간단히 설명하고자 한다.
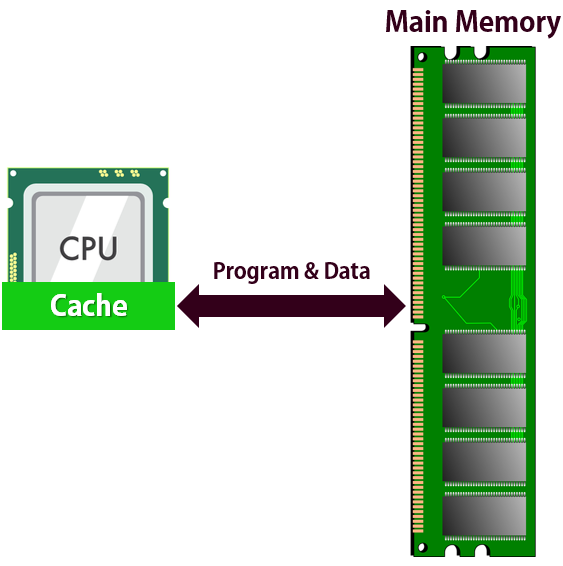
캐쉬 메모리는 CPU안의 작고 빠른 메모리이다. CPU가 메인 메모리에서 데이터를 읽거나 쓸때마다 해당 데이터는 캐쉬 메모리 안에 임시로 저장된다. 모든 메모리 데이터의 접근 순서는 다음과 같다.
- CPU는 캐쉬 메모리에서 데이터를 먼저 찾는다. 데이터가 있다면 메인 메모리에 접근하지 않는다.
- 캐쉬 메모리에 데이터가 없으면 메인 메모리에서 데이터를 가져온다.
Flush+Reload를 이해하기 위한 중요 포인트 둘은 다음과 같다.
#모든 메모리 접근 시 해당 데이터는 캐쉬 메모리에 새로이 저장된다.
#캐쉬 메모리로의 접근시간이 메인 메모리로의 접근시간보다 매우 짧다.
다시 처음으로 돌아가서 스펙터의 코드를 살펴보자.
해당 코드를 실행시키면, Branch prediction에 의해 타 프로그램의 비밀값인 array1[x]의 값이 캐쉬 메모리에 올라가게 된다. 여기서는 array1[x]가 75라고 가정해보자. 256은 여기서 메모리 페이지의 사이즈인데, 책으로 비유하자면 array1[x] 한 문장을 읽기위해 책의 한 페이지 일부를 캐쉬 메모리에 올린다고 생각하면 된다.
위 코드를 실행시키면 array2의 75페이지’만’ 캐쉬 메모리에 올릴 수 있다. 몇번째 페이지가 캐쉬메모리에 있는지 읽기 위해서는 위에서 언급한 포인트 중 두번째를 이용한다.
캐쉬 메모리로의 접근시간이 메인 메모리로의 접근시간보다 매우 짧다.
여기서 array2안에 256개의 메모리 페이지가 있다고 가정해보자. 만약 우리가 0페이지부터 255페이지까지 한번씩 읽어본다면, 75페이지를 읽는 속도만 유난히 빠를 것이다. 읽는 속도는 다음과 같다.
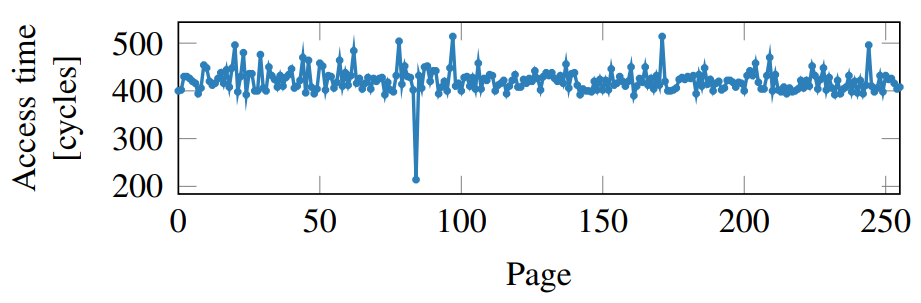
이렇게 접근 시간을 측정함으로써 array1[x]의 값을 알아낼 수 있다. 이 작업을 원하는 만큼 반복해서 어떤 메모리 영역의 데이터도 알아낼 수 있다.
본 포스트에서는 스펙터 공격의 원리를 설명하였다. 스펙터 공격의 가장 무서운 점은 현대 CPU의 핵심 성능향상 기술인 Branch Prediction과 캐시 메모리의 취약점을 이용한다는 것이다.
근 20년 간의 CPU 속도 향상에 크게 기여한 기술이 치명점 보안약점을 야기한다는 것은 참으로 아이러니하다.
– 본 포스트는 https://www.meltdownattack.com 에 있는 논문과 자료들을 토대로 작성되었습니다.
본 포스트에 대한 질문, 커멘트 등은 acsstudent28@gmail.com 으로 보내주세요.