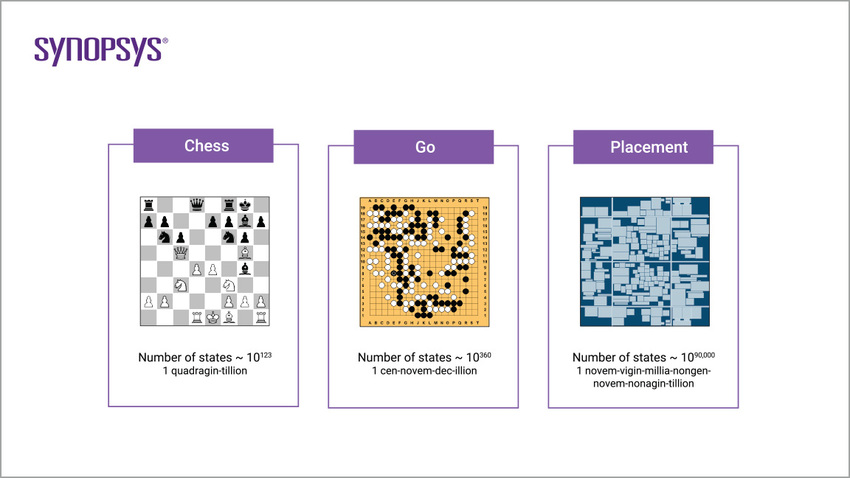
알파고 제로 (AlphaGo Zero) & Capture the Flag AI: 인공지능을 통해 인간의 전략을 이해하다

2016년 3월 9일, 서울의 포시즌스 호텔에서 있었던 세기의 대국은 전세계가 AI (Artificial Intelligent)에 다시금 주목하는 계기가 되었습니다. 바로 구글 딥마인드의 바둑 인공지능 알파고와 세계 최고의 바둑 기사 이세돌 9단의 대국 때문이었습니다. 이 대결에서 알파고는 세간의 예상을 뒤집으며 이세돌 9단에게 4:1 완승을 거뒀습니다.
그간 AI는 인간 프로기사를 상대로 단 한 번도 승리한적이 없었기에 이 결과는 전 세계에 큰 충격을 안겨주었습니다. 이 대결을 시작으로 다시 한 번 인공지능 르네상스가 도래하게 됩니다.
충격도 잠시, 구글 딥마인드팀은 발빠르게 알파고의 더 강력한 버전을 발표하게 됩니다. 약 2년간 다음 두 인공지능을 발표하게 됩니다.
2017: AlphaGo Zero (Mastering the Game of Go without Human Knowledge)
알파고보다 더 강한 알파고 제로는 인간의 기보없이 혼자서 바둑을 학습했습니다. 알파고 제로는 이세돌을 이긴 알파고 Lee보다 약 1500점 높은, 커제를 이긴 알파고 마스터버전보다 약 500점 더 높은 Elo Rating(실력을 가늠하는 점수)을 달성합니다. 다시말해 알파고 제로는 세상에서 가장 강한 바둑 플레이어라는 뜻입니다.
2018: Capture the Flag
2018년 딥마인드 팀은 2:2 Capture the Flag FPS게임을 플레이하는 인공지능을 발표합니다. 실시간으로 상대팀의 깃발을 뺏는 3D 게임에서 인공지능은 인간고수보다 약 400점 높은 ELO Rating을 기록합니다.
불과 수 년 전만 해도 인공지능이 바둑과 FPS게임에서 인간을 능가하는 것을 상상하기 어려웠습니다. 이 모든 것들이 지금은 현실이 되었습니다. 낙관적으로 볼 때, 앞으로 인공지능의 발전은 더욱 빠르게 진행될 것으로 예상됩니다. 그렇다면 인공지능은 곧 인간을 대체하게 되는 것인가요? 아직은 그렇지 않습니다.
본 포스트에서는 알파고 제로와 Captuer the Flag 인공지능을 소개하고, 이 기술들을 통해 가까운 미래에 인공지능이 인간의 삶에 어떠한 의미를 가지게 될지 소개하고자 합니다.
AlphaGo Zero

2017년 구글 딥마인드팀은 알파고의 새로운 버전인 알파고 제로를 발표합니다. 기존의 알파고는 약 16만개의 인간의 기보를 입력받아 바둑을 학습합니다. 반면 알파고 제로는 기보를 입력받지 않고 처음부터 시행착오를 거치며 학습합니다. 마치 바둑을 전혀 모르는 사람이 혼자서 수백년동안 바둑을 공부하는 방법과 같습니다.
놀랍게도 알파고 제로는 이세돌 9단을 이긴 기존의 알파고 Lee를 단 3일만에, 알파고 Lee 버전보다 조금 개선된 알파고 마스터를 21일만에 따라잡습니다. 다시 말하면 바둑을 아예 모르는 사람이 3일만에 이세돌 9단, 21일만에 커제 9단을 능가하는 실력을 갖추게 된 것입니다.
알파고 제로는 이에 만족하지 않고 40일만에 Elo 5000점(알파고 마스터는 약 4800점) 경지에 도달합니다. 마치 바둑의 신이 탄생한 것 같습니다.
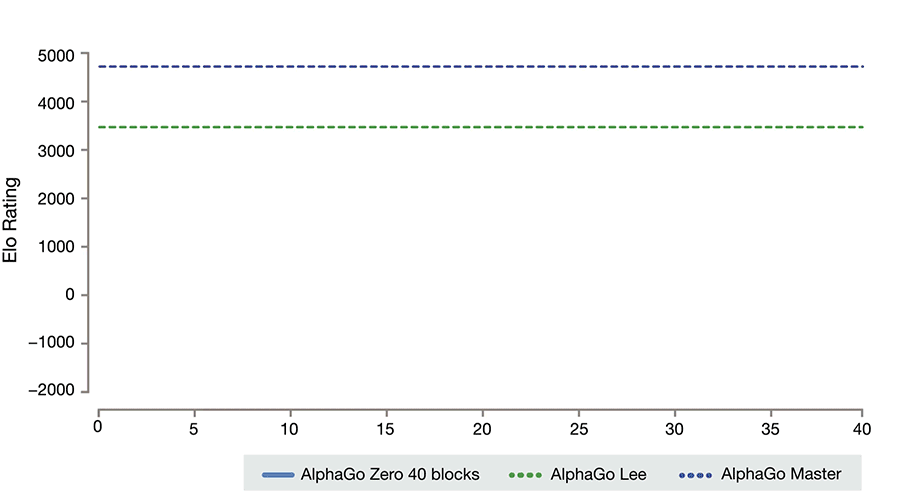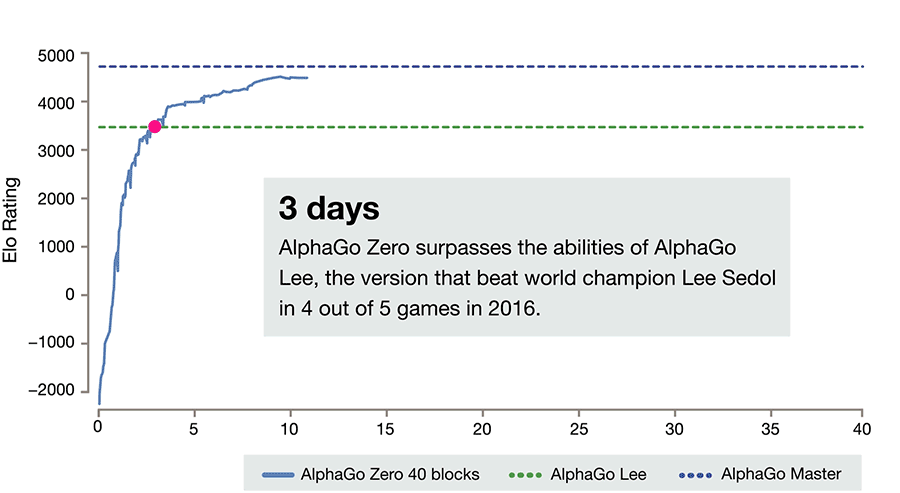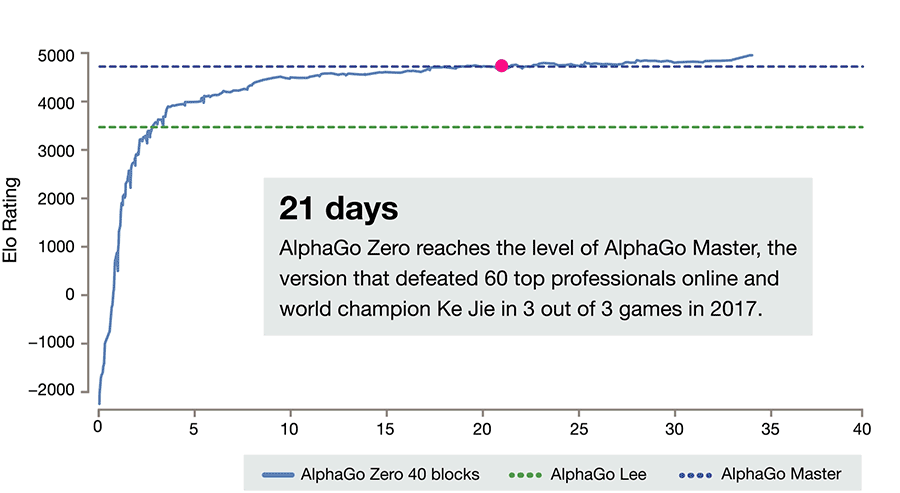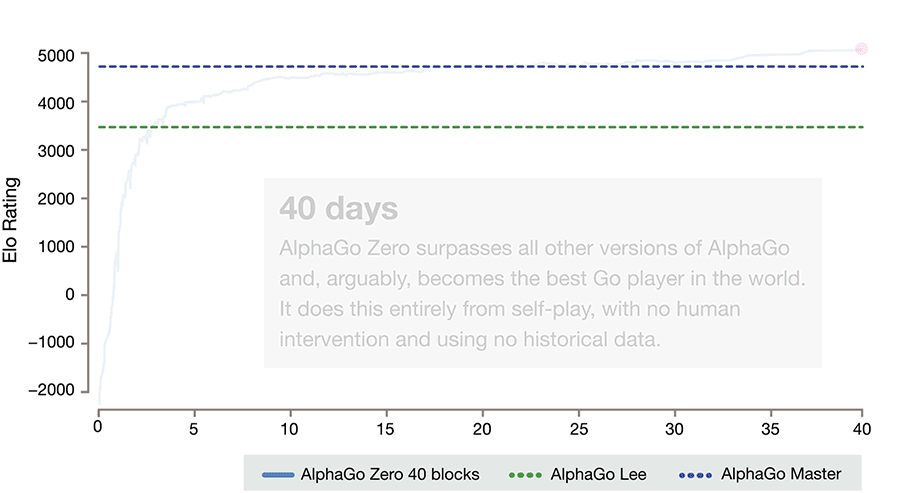
알파고 제로에 대해 저는 한 가지 우려를 마음속에 품고 있었습니다. 알파고 제로가 두는 바둑은 완전히 새로운 바둑일까? 사람의 수법과는 다를까 같을까? 만약 알파고 제로가 인간과 완전히 다른 수법의 바둑을 둔다면, 그리고 그 수법으로 알파고 제로가 인간을 완전히 능가한다면, 천년 넘짓 바둑을 두어 온 인간의 세월이 너무 허무해져 버릴 것 같았습니다. 제가 그동안 신선처럼 존경하던 프로 바둑 기사들의 노력이 하루아침에 부정당하는 느낌이 들 것 같았습니다.
아주 다행히도, 알파고 제로는 인간과 매우 유사하게 바둑을 플레이 했습니다.
학습 3시간 이내의 알파고 제로는 인간 초심자와 같은 모습이었습니다. 아주 귀퉁이 혹은 바둑판 한가운데에 돌을 마구 착수했습니다. 그러나 학습 19시간 이후로는 점점 사람과 같이 변해갔습니다. 인간과 거의 유사한 초반 포석 (초반 돌 포진)과 정석 (대체로 좋다고 알려져 많은 사람들이 두는 정수), 화점 (바둑판의 점), 소목 (화점의 옆), 3-3 (바둑판 귀퉁이 3X3 지점) 등 인간과 매우 비슷한 전략을 구사했습니다. 그간 인간이 두어온 바둑이 틀리지 않았음을, AI를 통해 역설적으로 알게된 것입니다.
약 70시간 이상의 학습을 거듭한 알파고 제로는 매우 복잡한 전략을 구사합니다. 마치 바둑의 신과 같은 모습입니다. 알파고 제로의 한 수 한 수에는 복잡한 의미들이 담기기 시작합니다. 심지어 한 수 한 수를 아예 다른 전장에 번갈아가며 두는 모습도 나타나는데, 이는 정말 놀랍습니다. 보통 인간은 한 번에 하나에서 둘의 전투에만 집중할 수 있습니다. 이는 뇌 용량의 한계때문입니다. 그러나 알파고는 세 가지 이상 전투를 자유롭게 넘나듭니다.

알파고 제로의 성공은 다음의 두 가지 의의를 나타냅니다.
1. 바둑에 대한 인간의 접근법이 옳았음을 입증합니다. 알파고 제로는 인간의 지식 없이 바둑을 학습했음에도 인간과 매우 유사한 바둑을 구사했습니다. 이는 바둑과 같이 아무도 해답을 모르는 문제에 대한 인간의 접근법을 검증하는 효과를 나타냅니다.
2. 인공지능이 인간보다 문제를 더 잘 풀 수 있는 가능성을 보여주었습니다. 알파고 제로는 결국 인간보다 훨씬 더 강한 바둑 실력을 갖게 됩니다. 이는 인간의 지식이 부족한 분야의 문제들도 인공지능이 해결할 수 있으며, 그로인해 사회발전을 크게 가속시킬 수 있는 가능성을 시사합니다.
한계점: 사실 인간세상의 문제들은 바둑보다 훨씬 더 복잡합니다. 따라서 알파고만 가지고 인간세상의 문제들을 모두 풀 수 있을 것이라 기대하는 것은 조금 섣부른 결론입니다.
Capture The Flag
Capture The Flag (이하 CTF) 게임은 고전게임의 하나로 각자의 팀이 상대편 기지 (Base)에 있는 깃발 (Flag)를 뺏어 자신의 기지로 가져오면 점수를 얻는 방식의 FPS 게임입니다. 간략히 게임 소개를 하면 다음과 같습니다.
- 상대 기지에 놓여있는 상대 깃발을 뺏어든다.
- 상대 깃발을 우리 기지로 가져온다.
- 우리 깃발이 우리 기지에 있는 상태에서 상대 깃발을 우리편 기지로 가져오면 점수를 얻는다.
- 우리 깃발을 든 상대편을 터치하면 우리 깃발이 즉시 우리 기지로 복귀한다.
CTF는 인공지능에게 바둑보다 더 어려운 게임입니다. 이유는 다음과 같습니다.
1. 취할 수 있는 액션의 수가 매우 많다. 인공지능은 3D화면을 통해 상황을 인지하고, 판단하고, 움직이고, 같은 편과 협력해야 합니다. 바둑과는 달리 이 모든 일은 실시간으로 이루어져야 합니다 (시간 제한이 존재합니다).
2. 정보가 제한되어 있고 비대칭이다. 바둑은 두 플레이어가 바둑판 위의 모든 정보를 알고있습니다. 반면, CTF에서는 각 플레이어는 자신이 보았던, 혹은 볼 수 있는 영역의 정보만을 습득합니다.
3. 협업을 해야한다. 협업은 팀원의 움직임도 고려해야 하므로 가능한 액션의 경우의 수를 큰 폭으로 늘립니다. 이 때문에 많은 학습 시간이 소요됩니다.
구글 딥마인드는 위와 같은 요소들을 고려하여 FTW (For The Win) 인공지능을 발표합니다. 40명의 인간 플레이어들을 포함한 토너먼트를 통해 (인간과 인공지능은 같은팀이 될수도, 다른팀이 될수도 있다) 테스트를 진행했다고 합니다.
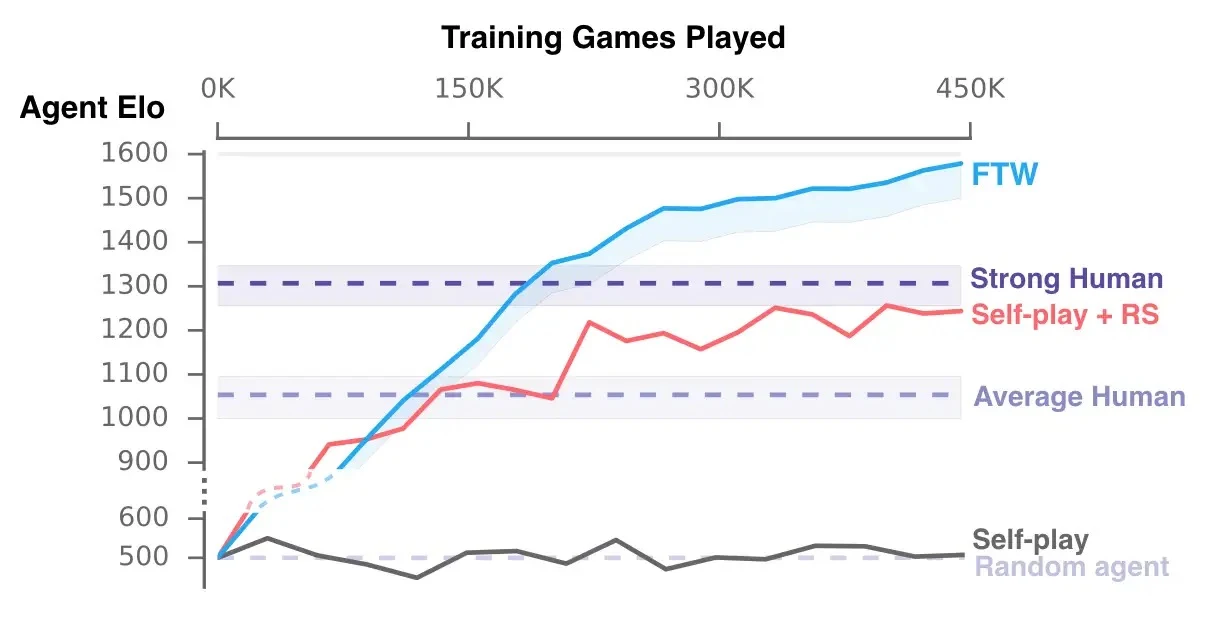
놀랍게도 CTF 게임마저 FTW 인공지능은 약 170,000게임의 플레이타임으로 인간 고수를 따라잡습니다. 심지어 300,000게임을 플레이한 후에는 인간고수를 아득히 뛰어넘습니다.
딥마인드의 CTF 게임에서의 성공은 인공지능이 바둑보다 어려운, 조금 더 현실세계에 가까운 문제도 해결할 수 있다는 가능성을 보여줍니다.
인간에게 인공지능의 의미: 실력에 따른 인공지능의 전략 변화
딥마인드는 알파고 제로와 CTF의 결과를 논문으로 발표했습니다. 본문도 재미있지만, 부록에 정말로 흥미로운 결과가 수록되어 있어 이곳에 소개합니다.
알파고 제로를 발표한 논문 <Mastering the Game of Go without Human Knowledge>의 부록에서는 알파고 제로가 사용한 정석 (많이 사용되어 정수라고 불리는 전략)의 빈도수를 그래프로 보여줍니다. 논문에는 약 10여 가지 전략을 보여주는데, 여기에서는 두 가지 예를 소개하겠습니다.
Pincer 3-3 Point
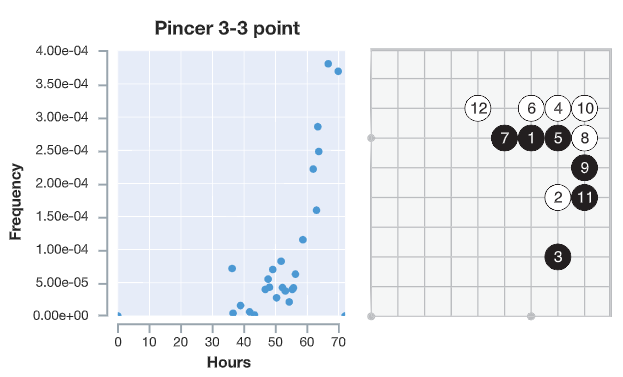
Pincer 3-3 point 전략은 한국에서는 ‘날일자 걸침’으로 알려져 있습니다.
논문에 보면 30시간 까지 학습한 (초보) 알파고 제로는 날일자 걸침을 전혀 사용하지 않습니다. 학습 30시간이 넘은 중수 알파고 제로는 날일자 걸침을 서서히 사용하더니, 학습 60시간이 넘어가는 고수 알파고 제로는 날일자 걸침을 아주 즐겨 쓰는 것을 볼 수 있습니다.
이는 무엇을 의미할까요? 날일자 걸침은 반드시 써야할 필승 전략이라 추론해볼 수 있습니다. 알파고 제로는 날일자 걸침을 아주 좋아합니다!
3-3 Invasion
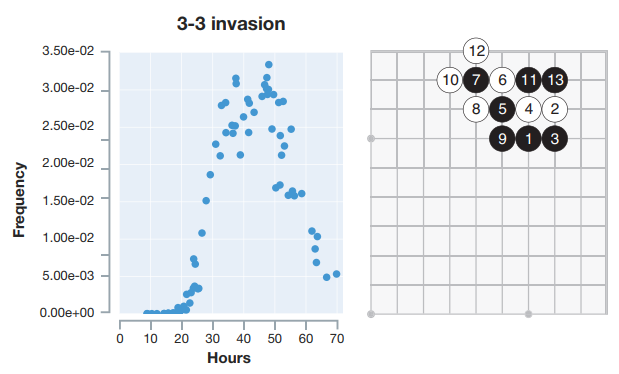
3-3 침입으로 잘 알려진 전술입니다. 바둑 애호가들 사이에서는 아주 즐겨쓰이면서 논란이 많은 전술입니다. 일단 3-3 침입을 사용하면 상대방의 집을 일정 이상 깨는 것이 보장되어 있습니다. 그런데 상대방의 세력을 두텁게 한다는 단점이 있어 고수들은 3-3 침입을 자제하는 경향도 보여왔습니다.
알파고 제로의 학습시간이 약 20-30시간을 넘어가면서부터 폭발적으로 쓰이기 시작합니다. 약 40시간을 학습한 중급 알파고 제로의 경우에서는 매우 잦은 빈도로 3-3 침입을 사용하는 것을 볼 수 있습니다.
아주 흥미롭게도, 알파고 제로의 학습시간이 60시간을 넘어가면서부터는 3-3침입의 사용빈도가 매우 큰 폭으로 떨어집니다. 이는 3-3침입의 가치가 고수 플레이어 레벨에서는 크지 않을 수 있음을 시사합니다. 인간 고수들의 경험이 한 번 더 검증되는 순간입니다!
CTF게임에서도 매우 유사한 결과를 찾아볼 수 있습니다. 딥마인드는 CTF게임을 학습한 인공지능이 다음과 같이 크게 세 가지의 전략을 주로 구사하는 것을 확인할 수 있었습니다: Home Base Defence (집 지키기), Opponent Base Camping (상대 기지 캠핑), Teammate Following (우리편 따라다니기).

이 전략들을 보며 무슨 생각이 드시나요? 우리도 이 게임을 플레이 했다면 떠올릴 법한 전략이지 않은가요? 그렇다면 과연 고수 AI는 어떤 전략을 선호했을까요?
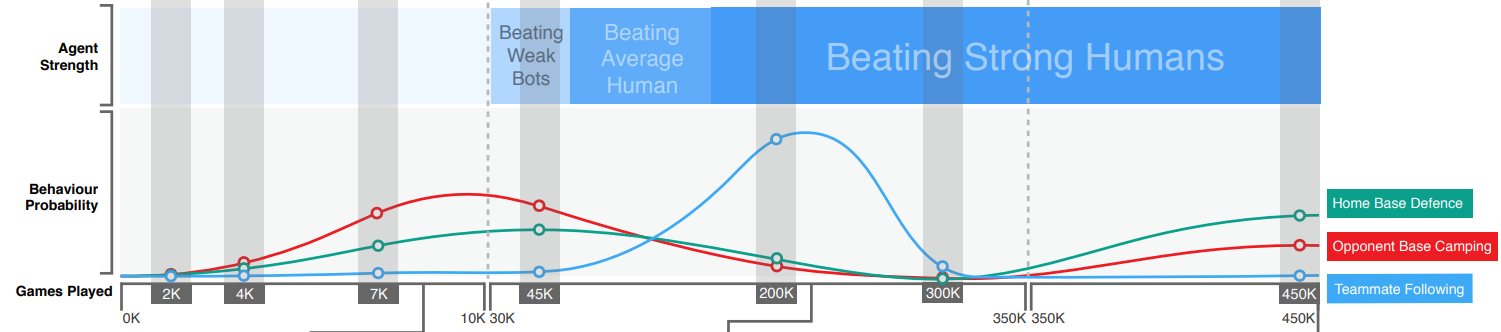
위 그래프는 CTF 게임플레이 시간에 따른 인공지능의 전략 사용 빈도(확률)을 나타냅니다. 약 200,000게임을 플레이한 CTF 인공지능은 Teammate Following (같은편 따라다니기) 전략을 압도적으로 많이 사용했습니다.
그러나 약 300,000게임플레이를 넘어가며 고수단계로 진입한 CTF 인공지능은 Home Base Defence (내 기지 지키기) 와 Opponent Base Camping (상대편 기지에 진치기)를 섞어 사용했고 Teammate Following 전략은 매우 적게 사용했습니다. 그 중에서도 Home Base Defence 전략을 가장 많이 사용했습니다.
이 그래프 또한 각 전략의 가치의 난이도를 간접적으로 시사합니다. Teammate Following같은 경우는 중수들이 매우 간단하면서도 강력하게 사용할 수 있는 전략이라 추론해볼 수 있고, Home Base Defence의 경우는 고수레벨에서 사용하기 좋은 전략이라 유추해볼 수 있습니다.
결론: 인공지능은 우리의 선택을 더 객관적으로
본 포스트에서는 알파고 제로와 Capture The Flag 게임 인공지능을 간단히 소개하고, 각 인공지능이 공통적으로 보였던 전략에 대한 분석을 소개했습니다. 두 인공지능은 게임을 학습하며 특정 전략을 스스로 발견하고 활용하였으며, 학습시간과 실력에 따라 각 전략을 다른 빈도로 사용하는 모습을 보여주었습니다. 그러나 두 인공지능이 보여준 전략들은 우리에게 있어 새롭고 특별한 것은 아니었습니다. 3-3 침입과 같은 알파고가 보여준 전략들은 이미 인간도 충분히 사용해왔습니다.
인공지능을 통해 우리는 우리가 사용한 전략들의 가치를 다시 한 번 검증할 수 있었습니다. 인간사회에서는 특정 전략/전술에 있어 주관적 평가가 많았습니다. 예를 들어 조훈현 9단이 화려한 행마와 공격형 바둑으로 각종 타이틀을 석권하자, 많은 사람들이 조훈현 9단의 행마와 공격바둑을 으뜸이라 여겼습니다. 이창호 9단의 시대에는 견실하고 실리를 추구하는 수비형 바둑이 각광을 받았습니다.
인공지능 이전의 기원에서는 어떤 바둑이 최강인지 뜨거운 토론을 이어왔습니다. 이와 같이 인간은 전략과 전술의 가치에 대해 많은 논쟁과 토론을 나눕니다. 술 한 잔과 함께 친구, 동료들과 나누는 논쟁은 많은 이에게 즐거움의 대상이 되기도 합니다.
알파고 제로와 FTW 인공지능은 단순히 게임을 잘 플레이 하는 것에 그치지 않고 우리에게 바둑과 CTF게임에 대한 깊은 이해 (Insight) 를 제공합니다. 각 전략들의 사용빈도와 함께, 이 게임들을 어떻게 플레이해야 하는지, 그리고 어떤 전술이 더 가치가 있는지 통계적 데이터와 함께 조금 더 객관적으로 우리에게 나타냅니다.
위 사례들을 통해, 인공지능이 인간 사회의 많은 분야에서 보다 객관적 평가를 제공할 가능성을 엿볼 수 있습니다. 예를들어, 축구경기에서 4-2-3-1 포메이션이 과연 최고의 포메이션인지 인공지능이 데이터를 기반으로 평가를 내릴 수 있을 것입니다. 전쟁 시뮬레이션을 통해 최적의 전술을 찾고 그 동안 인류가 사용해온 전쟁 전술에 대한 평가도 내려볼 수 있을지 모릅니다. 먼 미래에는 정부 정책의 평가에도 도움을 줄 것입니다.
본 포스트는 구글에서 공개한 블로그, 논문들을 토대로 작성되었습니다.
본 포스트에 대한 코멘트, 질문 등은 acsstudent28@gmail.com 보내주시면 감사하겠습니다.
참고문헌
- Silver, David, et al. “Mastering the game of Go without human knowledge.” Nature, 2017.
- AlphaGo Zero: Learning from the Scratch, url: https://deepmind.com/blog/alphago-zero-learning-scratch/
- Max Jaderberg et al., Human-level performance in first-person multiplayer games with population-based deep reinforcement learning, 2018
- Capture the Flag: the emergence of complex cooperative agents, url: https://deepmind.com/blog/capture-the-flag/