애플 M1 칩은 왜 그렇게 빠른가?: 애플 M1 성능 비결
애플 M1 프로세서의 반응이 폭발적입니다. 이 프로세서는 2020년 말부터 출시된 맥북 에어, 맥미니, 맥북 프로 제품군에 탑재되었는데, 엄청난 전력 대 성능 비(전성비)를 자랑하며 소비자들을 매료시켰습니다. M1을 탑재한 맥북 에어는 인텔 프로세서를 탑재한 맥북 에어에 비해 약 3배(Geekbench 멀티코어 점수 기준) 더 높은 성능을 보입니다. 동시에 배터리 시간은 2배 가까이 향상되었습니다. 놀라운 전성비 향상입니다. 어떻게 이러한 향상이 가능했을까요?
사실 M1의 전성비 비결은 정확히 알려지지 않았습니다. 애플은 프로세서의 구조 정보를 외부에 전혀 공개하지 않습니다. 그럼에도 불구하고 이전 프로세서들에서 밝혀진 정보들을 기반으로 M1의 전성비 비결을 추론해본 기사들이 존재합니다. 본 글에서는 이 기사들을 종합해 추론한 애플 M1의 강력한 전성비 비결을 설명합니다.
Apple M1
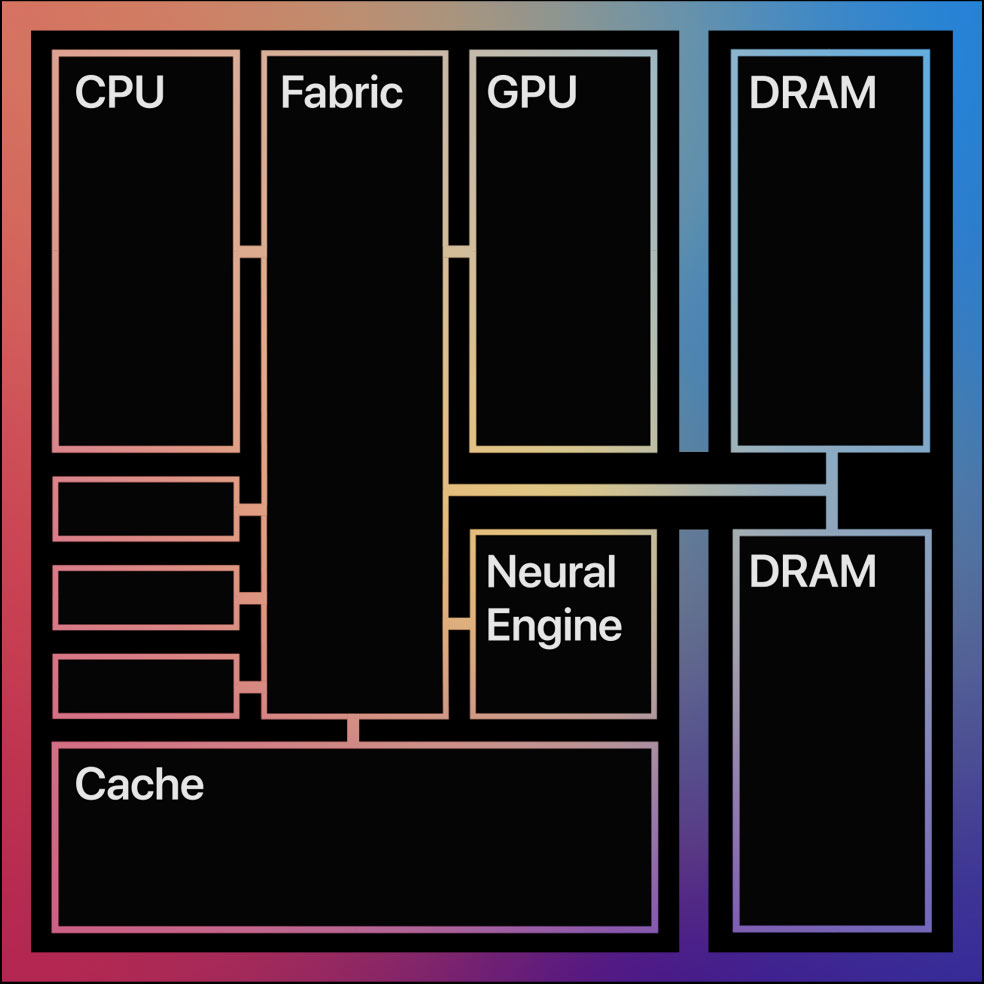
먼저 M1의 구조를 간략히 설명하겠습니다. 애플 M1은 애플 실리콘이라 불리는 애플이 설계한 ARM 기반의 System-on-Chip (SoC) 중 하나입니다. SoC란 컴퓨터의 모든, 혹은 대부분의 컴포넌트가 한 칩에 집적된 집적회로를 지칭합니다. SoC는 주로 CPU, GPU, Cache, Main Memory, Modem을 포함하는데, 특별히 M1은 Neural Engine이라 불리는 신경망 가속기를 포함하는 것이 특징입니다. M1의 CPU에는 총 8개의 Core가 탑재되어 있습니다. 그 중 연산 능력이 강력한 4개의 Core들은 Firestorm이라 부르고, 비교적 약한 4개의 Core들을 Icestorm이라 부릅니다. 애플의 OS는 이들을 인식하여 계산이 많은 작업은 Firestorm에서, 그렇지 않은 작업은 Icestorm에서 실행합니다
Why Is M1 So Fast?
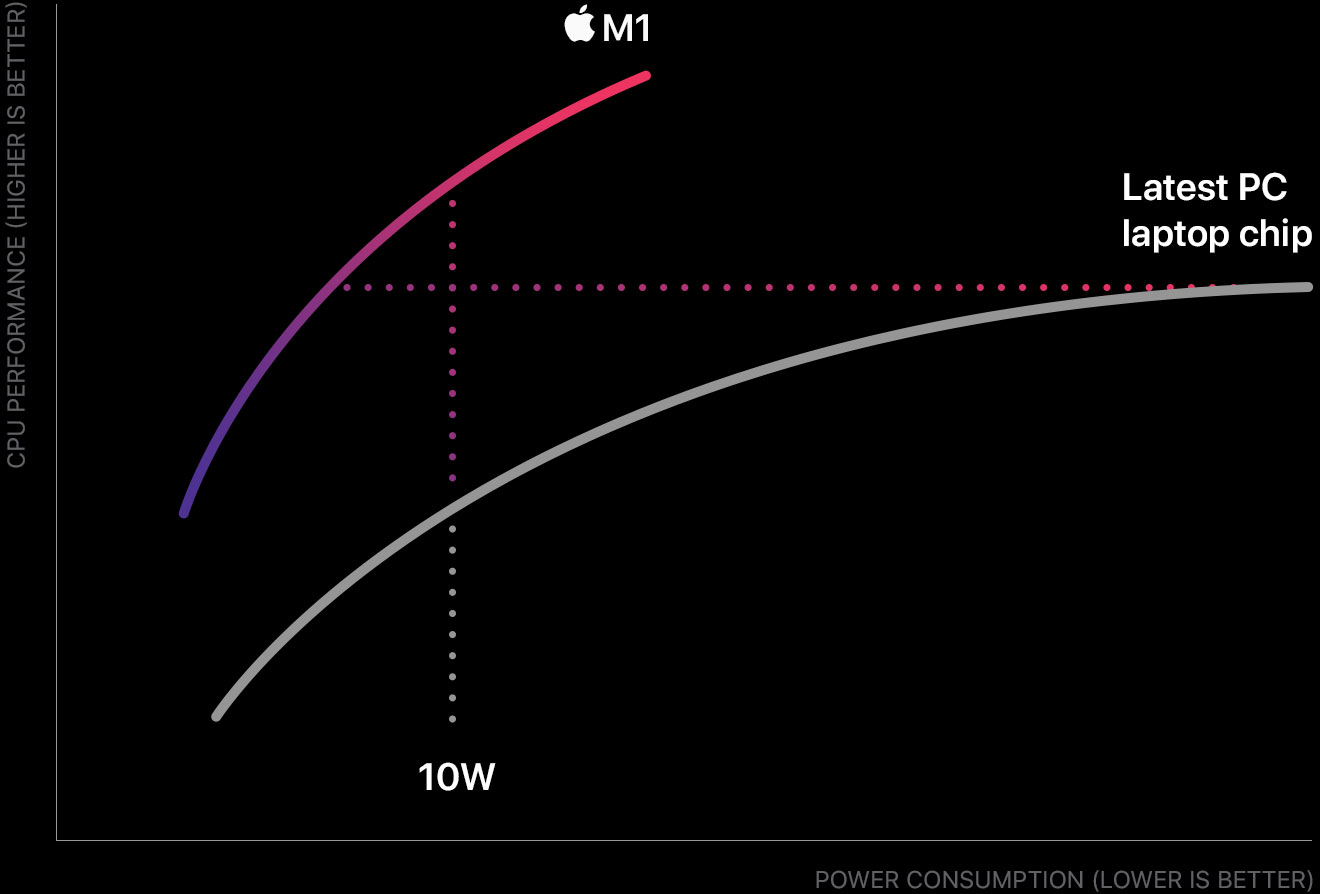
M1 전성비의 가장 큰 비결은 높은 Instruction Level Parallelism (ILP) 활용 입니다. ILP는 컴퓨터의 명령어들이 병렬적으로 실행될 수 있는 정도를 의미합니다. 프로세서가 ILP를 더 잘 활용할수록 같은 시간 동안 더 많은 명령어들을 실행할 수 있습니다. 한 Cycle에 여러 명령어를 실행하는 CPU Pipelining, 순서와 상관없이 현재 실행할 수 있는 명령어부터 실행하는 Out-of-Order Execution 등이 대표적인 ILP 활용 기법입니다. ILP를 활용하면 CPU의 Clock Speed를 높이지 않고도 컴퓨터의 성능(Throughput)을 향상시킬 수 있습니다. CPU의 전력 소비는 Clock Speed에 비례하여 높아지기 때문에, 이는 전성비 향상으로 이어집니다.
인텔과 AMD도 당연히 ILP를 열심히 활용합니다. 그러나 그들의 복잡한 아키텍쳐가 발목을 잡았습니다. 인텔과 AMD가 사용하는 x86과 x64 ISA는 대표적인 Complex Instruction Set Computer (CISC)입니다. CISC의 철학은 하나 하나의 명령어가 복잡한 일을 수행하도록 하는 것입니다. 비교적 컴파일러가 할일이 적고 프로그램의 길이가 짧아진다는 장점이 있습니다. 그러나 각 명령어 구조가 복잡하기 때문에 단점 또한 많이 존재합니다. ARM은 대표적인 Reduced Instruction Set Computer (RISC)입니다. RISC 철학은 각 명령어를 단순하게 설계하고, 단순한 명령어를 조합해 프로그램을 비교적 복잡하게 구성합니다. 아래의 예를 통해 ARM ISA를 사용하는 M1 칩의 전성비 비결을 살펴보겠습니다.
Instruction Decoder
ARM ISA를 사용하는 애플 실리콘은 x86과 x64 ISA를 사용하는 인텔과 AMD 프로세서에 비해 ILP를 활용하기가 수월합니다. ARM 명령어들의 길이는 고정적이고, 형식도 비교적 단순합니다. 반면 x86과 x64 명령어들의 길이는 가변적이며, 형식도 복잡합니다. 가변 길이의 복잡한 명령어를 사용하면 명령어의 시작과 끝을 예측하기가 어렵습니다.
예를 들어 보겠습니다. 8바이트 고정 명령어 길이를 사용하는 ARM CPU를 가정해보겠습니다. 이 CPU가 L1 명령어 캐쉬 메모리에서 64바이트의 명령어 묶음(Chunk)를 읽어오면, 8개의 명령어로 쉽게 쪼갤 수 있습니다. 명령어의 시작과 끝이 고정되어 있기 때문입니다. 반면 명령어 길이가 가변적인 x86 CPU는 64바이트를 어떻게 8개의 명령어로 쪼개야 할지 알기가 어렵습니다. 대략 Decoder 32개를 사용하면 평균 4개 정도의 명령어를 동시에 실행 수 있습니다. 이는 매우 낮은 효율입니다. 따라서 인텔과 AMD CPU 구조에서는 Decoder 수를 늘리기가 어렵습니다.
단순한 Decoder 구조 덕분에 애플 실리콘에서는 인텔 프로세서보다 많은 명령어 Decoder를 사용합니다. 2020년 말에 출시된 애플의 A14는 8개의 명령어 Decoder를 사용합니다. 애플 M1은 같거나 더 많은 Decoder를 사용할 것이라 예상됩니다. 반면 인텔 프로세서는 그 절반인 4개의 Decoder를 사용합니다. 더 많은 Decoder 덕분에 애플은 훨씬 더 큰 Reorder Buffer (ROB)를 사용할 수 있습니다. ROB는 Out-of-Order Execution 기법을 사용하는 CPU에서 실행 대기 명령어를 저장하는 버퍼입니다. ROB에 대기 중인 명령어가 많을수록 CPU가 쉬지않고 명령어를 수행할 수 있습니다. 따라서 가득 채울 수만 있다면 ROB가 클수록 성능이 향상될 수 있습니다. 애플의 많은 Decoder는 큰 ROB를 훨씬 더 빠르게 채웁니다. A14의 ROB 크기는 약 630개 명령어 크기입니다. M1은 더 클 것으로 예상됩니다. 반면 인텔의 Sunny Cove와 Willow Cove 프로세서들의 ROB크기는 그 절반가량인 352개 명령어 크기 입니다.
Parallelism, Parallelism, Parallelsim!
또한 애플은 Memory 시스템의 구조 또한 Parallelism 활용을 극대화하는 방향으로 설계했습니다. 첫째로 애플은 매우 큰 L1 명령어 캐쉬를 사용합니다. A14의 L1 명령어 캐쉬의 크기는 192KB입니다. 이는 인텔 L1 명령어 캐쉬 크기의 6배입니다. 큰 명령어 캐쉬는 더 많은 명령어를 저장할 수 있기 때문에, ILP를 더욱 활용하려는 애플의 의도를 엿볼 수 있습니다. 또한 SoC의 장점을 살려 CPU와 GPU가 공유하는 Unified Memory Architecture (UMA)를 채택하였습니다. 애플 실리콘의 UMA는 CPU와 GPU의 전용 Memory 영역이 따로 나눠지지 않은 것이 큰 특징입니다. 기존 SoC에서는 CPU, GPU, Modem 등의 모듈들이 Memory 영역을 나눠서 사용했습니다. 그러나 UMA에서는 CPU, GPU, Neural Engine, Cache들이 영역 구분없이 데이터에 접근할 수 있습니다. 결과적으로 데이터 이동을 크게 줄이고 Data Parallelism을 더욱 활용할 수 있습니다.
요약하면, 애플 M1 프로세서의 전성비 비결은 Parallelism 활용 극대화라고 말할 수 있습니다. 이는 애플이 아이폰, 아이패드를 통해 쌓은 SoC 설계 노하우 덕에 가능합니다. 애플 실리콘은 이제 시작입니다. 2021년에 출시될 새로운 아이맥, 맥북프로 등은 애플 M1의 후속 버전인 M1X, M2를 탑재한다고 합니다. 애플의 새로운 칩이 아이맥에서 성공을 거둘 경우, 데스크탑 시장에서도 점유율을 크게 가져올 수 있습니다. 향후 컴퓨터 시장에서 애플 실리콘의 행보가 기대됩니다.
참고자료
- https://www.apple.com/mac/m1/
- https://community.cadence.com/cadence_blogs_8/b/breakfast-bytes/posts/decoders
- https://debugger.medium.com/why-is-apples-m1-chip-so-fast-3262b158cba2#:~:text=The%20fast%20general%2Dpurpose%20CPU,the%20fastest%20AMD%20Ryzen%20cores.
- https://www.pro-tools-expert.com/production-expert-1/why-the-apple-m1-chip-is-so-fast
- https://www.anandtech.com/show/16226/apple-silicon-m1-a14-deep-dive